<style>.reveal p{text-align:left;}</style> # 排序 [排序](http://39.99.183.126:8888/p/CCFPB06D12) --- ## 定义 **排序算法**(英语:Sorting algorithm)是一种将一组特定的数据按某种顺序进行排列的算法。排序算法多种多样,性质也大多不同。 --- ## 性质 ### 稳定性 稳定性是指相等的元素经过排序之后相对顺序是否发生了改变。 拥有稳定性这一特性的算法会让原本有相等键值的纪录维持相对次序,即如果一个排序算法是稳定的,当有两个相等键值的纪录 $R$ 和 $S$,且在原本的列表中 $R$ 出现在 $S$ 之前,在排序过的列表中 $R$ 也将会是在 $S$ 之前。 基数排序、计数排序、插入排序、冒泡排序、归并排序是稳定排序。 选择排序、堆排序、快速排序、希尔排序不是稳定排序。 --- ### 时间复杂度 时间复杂度用来衡量一个算法的运行时间和输入规模的关系,通常用 $O$ 表示。 简单计算复杂度的方法一般是统计「简单操作」的执行次数,有时候也可以直接数循环的层数来近似估计。 时间复杂度分为最优时间复杂度、平均时间复杂度和最坏时间复杂度。OI 竞赛中要考虑的一般是最坏时间复杂度,因为它代表的是算法运行水平的下界,在评测中不会出现更差的结果了。 基于比较的排序算法的时间复杂度下限是 $O(n\log n)$ 的。 当然也有不是 $O(n\log n)$ 的。例如,计数排序 的时间复杂度是 $O(n+w)$,其中 $w$ 代表输入数据的值域大小。 --- ### 空间复杂度 与时间复杂度类似,空间复杂度用来描述算法空间消耗的规模。一般来说,空间复杂度越小,算法越好。 --- # 冒泡排序 --- 1176 [YBTJ1176 谁考了第k名](http://39.99.183.126:8888/p/gYBTJ1176) ## 定义 冒泡排序(英语:Bubble sort)是一种简单的排序算法。由于在算法的执行过程中,较小的元素像是气泡般慢慢「浮」到数列的顶端,故叫做冒泡排序。 --- ## 过程 它的工作原理是每次检查相邻两个元素,如果前面的元素与后面的元素满足给定的排序条件,就将相邻两个元素交换。当没有相邻的元素需要交换时,排序就完成了。 经过 $i$ 次扫描后,数列的末尾 $i$ 项必然是最大的 $i$ 项,因此冒泡排序最多需要扫描 $n-1$ 遍数组就能完成排序。 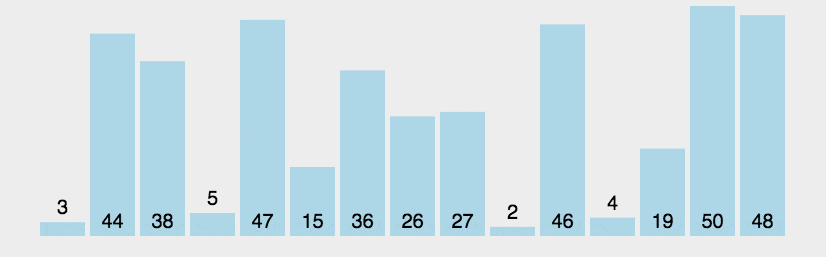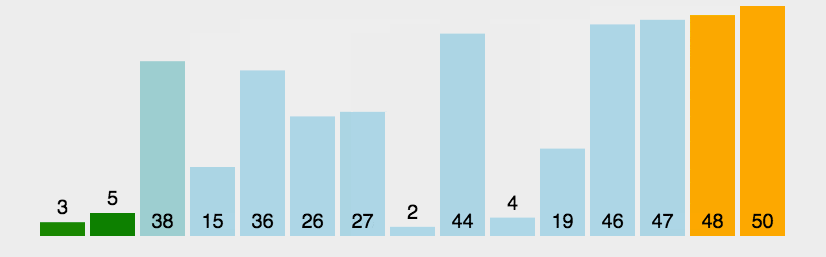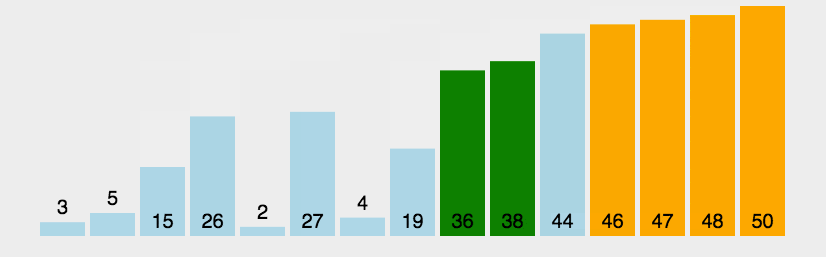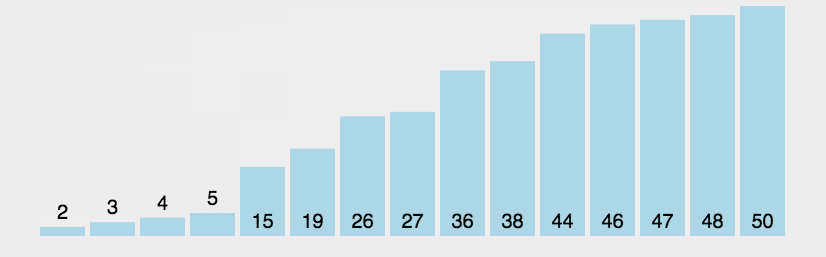 --- ## 性质 ### 稳定性 冒泡排序是一种稳定的排序算法。 --- ### 时间复杂度 在序列完全有序时,冒泡排序只需遍历一遍数组,不用执行任何交换操作,时间复杂度为 $O(n)$。 在最坏情况下,冒泡排序要执行 $\frac{(n-1)n}{2}$ 次交换操作,时间复杂度为 $O(n^2)$。 冒泡排序的平均时间复杂度为 $O(n^2)$。 --- ## 代码实现 ### C++ ```cpp // C++ Version // 假设数组的大小是n+1,冒泡排序从数组下标1开始 void bubble_sort(int *a, int n) { bool flag = true; while (flag) { flag = false; for (int i = 1; i < n; ++i) { if (a[i] > a[i + 1]) { flag = true; int t = a[i]; a[i] = a[i + 1]; a[i + 1] = t; } } } } ``` --- # 选择排序 --- 1177 [YBTJ1177 奇数单增序列](http://39.99.183.126:8888/p/gYBTJ1177) ## 定义 选择排序(英语:Selection sort)是一种简单直观的排序算法。它的工作原理是每次找出第 $i$ 小的元素(也就是 $A_{i..n}$ 中最小的元素),然后将这个元素与数组第 $i$ 个位置上的元素交换。  --- ## 性质 ### 稳定性 由于 swap(交换两个元素)操作的存在,选择排序是一种不稳定的排序算法。 ### 时间复杂度 选择排序的最优时间复杂度、平均时间复杂度和最坏时间复杂度均为 $O(n^2)$。 --- ## 代码实现 ### C++ ```c++ // C++ Version void selection_sort(int* a, int n) { for (int i = 1; i < n; ++i) { int ith = i; for (int j = i + 1; j <= n; ++j) { if (a[j] < a[ith]) { ith = j; } } std::swap(a[i], a[ith]); } } ``` --- # 插入排序 --- ## 定义 插入排序(英语:Insertion sort)是一种简单直观的排序算法。它的工作原理为将待排列元素划分为「已排序」和「未排序」两部分,每次从「未排序的」元素中选择一个插入到「已排序的」元素中的正确位置。 --- 一个与插入排序相同的操作是打扑克牌时,从牌桌上抓一张牌,按牌面大小插到手牌后,再抓下一张牌。  --- ## 性质 ### 稳定性 插入排序是一种稳定的排序算法。 --- ### 时间复杂度 插入排序的最优时间复杂度为 $O(n)$,在数列几乎有序时效率很高。 插入排序的最坏时间复杂度和平均时间复杂度都为 $O(n^2)$。 --- ## 代码实现 ### C++ ```cpp // C++ Version void insertion_sort(int* a, int n) { // 对 a[1],a[2],...,a[n] 进行插入排序 for (int i = 2; i <= n; ++i) { int key = a[i]; int j = i - 1; while (j > 0 && a[j] > key) { a[j + 1] = a[j]; --j; } a[j + 1] = key; } } ``` --- # 计数排序 * [P420 分数线划定](http://39.99.183.126:8888/p/g420) * [CSPJ2020B 直播获奖](http://39.99.183.126:8888/p/gCSPJ2020B) --- ## 定义 计数排序(英语:Counting sort)是一种线性时间的排序算法。 --- ## 过程 计数排序的工作原理是使用一个额外的数组 $C$,其中第 $i$ 个元素是待排序数组 $A$ 中值等于 $i$ 的元素的个数,然后根据数组 $C$ 来将 $A$ 中的元素排到正确的位置。[^ref1] --- 它的工作过程分为三个步骤: 1. 计算每个数出现了几次; 2. 求出每个数出现次数的 [前缀和](http://39.99.183.126:8888/blog/2/64707b8118d26a69f823902b#1685093249823); 3. 利用出现次数的前缀和,从右至左计算每个数的排名。 --- ### 计算前缀和的原因 *阅读本章内容只需要了解前缀和概念即可* 直接将 $C$ 中正数对应的元素依次放入 $A$ 中不能解决元素重复的情形。 我们通过为额外数组 $C$ 中的每一项计算前缀和,结合每一项的数值,就可以为重复元素确定一个唯一排名: 额外数组 $C$ 中每一项的数值即是该 key 值下重复元素的个数,而该项的前缀和即是排在最后一个的重复元素的排名。 如果按照 $A$ 的逆序进行排列,那么显然排序后的数组将保持 $A$ 的原序(相同 key 值情况下),也即得到一种稳定的排序算法。 ---  --- ## 性质 ### 稳定性 计数排序是一种稳定的排序算法。 --- ### 时间复杂度 计数排序的时间复杂度为 $O(n+w)$,其中 $w$ 代表待排序数据的值域大小。 --- ## 代码实现 ### C++ ```cpp // C++ Version const int N = 100010; const int W = 100010; int n, w, a[N], cnt[W], b[N]; void counting_sort() { memset(cnt, 0, sizeof(cnt)); for (int i = 1; i <= n; ++i) ++cnt[a[i]]; for (int i = 1; i <= w; ++i) cnt[i] += cnt[i - 1]; for (int i = n; i >= 1; --i) b[cnt[a[i]]--] = a[i]; } ```